El software NVivo es una herramienta de análisis de información cualitativa que permite analizar datos de documentos de distinta tipología: textuales, multimediales, bibliográficos, etc. Permite organizar, visualizar y analizar información a partir de procesos de codificado, en función de identificar patrones y características de un documento. Para este caso puntual, se utilizó NVivo para la codificación y análisis de una entrevista realizada a un coordinador editorial de un sello editorial con publicaciones en ciencias sociales. El objetivo perseguido con la entrevista fue “Conocer las perspectivas de un editor o coordinador editorial inicialmente frente a su ejercicio profesional en un marco institucional y disciplinar en general, y luego frente a su participación y comprensión de una colección editorial en específico. El hilo conductor de la entrevista parte de las trayectorias personales del entrevistado, para luego enfocarse en las prácticas de edición en un marco institucional”.
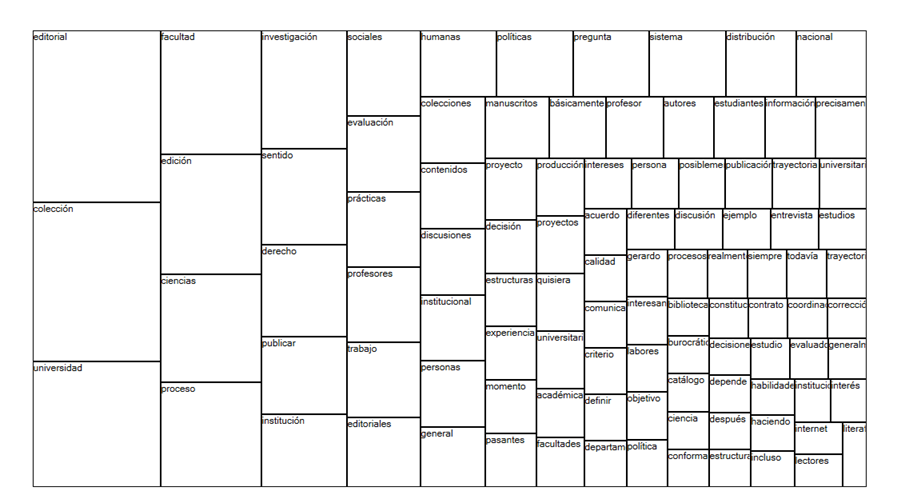
El procesamiento de información en el software revela inicialmente los términos de mayor frecuencia. Las siguientes gráficas (nube de palabras y mapa de ramificado) muestran los términos de mayor frecuencia en el documento (se excluyen palabras vacías y se recorta la búsqueda a los primeros doce términos, sin lematizar). Se observa un uso especializado de términos y categorías del contexto editorial en relación con estructuras institucionales universitarias.

El proceso de codificado posterior de la información (o codificado sustantivo) arrojó un conjunto de 13 elementos, cuyas gráficas se muestran a continuación. La codificación se realizó de manera previa en la herramienta Taguette (agrupamiento de códigos en categorías sustantivas). Se destacan categorías centrales como “contexto y estructura de Facultad” o “contexto y estructura institucionales”, así como relaciones emergentes entre categorías.
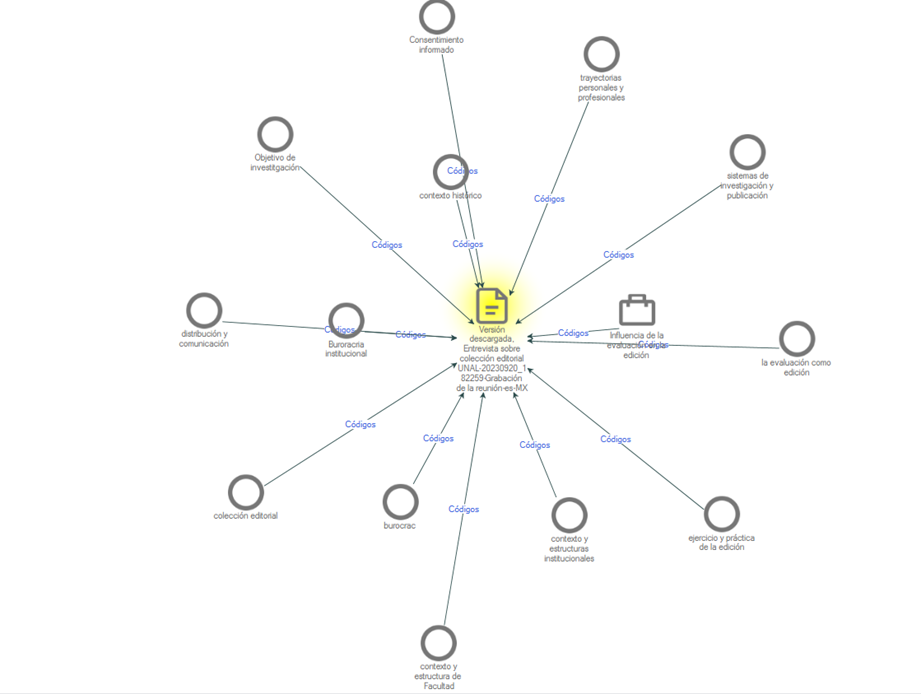

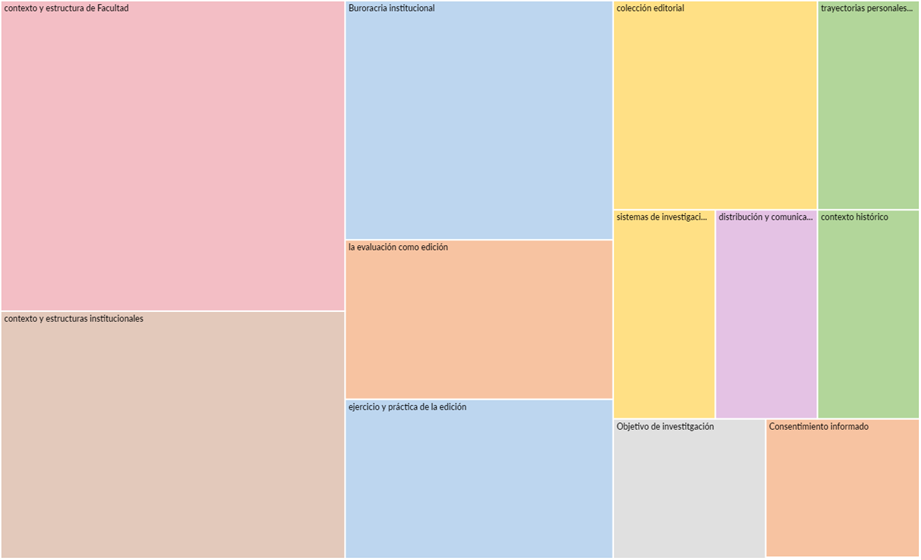
Las categorías son tanto emergentes como preestablecidas. La justificación del proceso de codificado sustantivo fue pensada en ejercicio previo con Taguette: “El proceso de codificado de datos cualitativos permite hacer una organización sistemática de la información que favorece el proceso de interpretación. La asignación de códigos y el establecimiento de las categorías centrales emergen como respuesta a las preguntas intencionadas del investigador, y por eso se vuelven recursos de navegación y ordenamiento funcionales. El etiquetado y la categorización no son otra cosa que procedimientos lógicos de organización jerárquica de la información, a partir de lo cual es posible consolidar resultados adecuados según los intereses y preguntas de investigación. Las operaciones deductivas e inductivas que emergen en un proceso de codificación son también operaciones epistémicas típicas en los procesos de lectura y escritura”. El proceso de etiquetado sustantivo revela características significativas en el orden del discurso: una permanente ubicación de la práctica de la edición en contextos y estructuras institucionales particulares, que determinan y condicionan su naturaleza y proceso; una amplificación de la concepción de la edición que la conecta con sistemas institucionales como al evaluación y la investigación; una crítica permanente al modelo vertical de edición e institucional, que condiciona no siempre positivamente el desarrollo editorial; una permanente enunciación de las trayectorias personales y profesionales que devinieron factores del ejercicio editorial, etc.
Ahora bien, una codificación automática muestra un espectro más amplio y diverso de términos o categorías recurrentes en la entrevista, así como sus contextos de enunciación puntuales. Este tipo de agrupamiento de información permite dar cuenta de los contextos de uso de léxico especializado. En este sentido, es un resultado de tipo lexicométrico revelador que revela indicios categoriales y conceptuales implícitos en el contenido:

La creación de memos se constituye en una herramienta adicional del software, a través de la cual se puede realizar reflexiones cualitativas asociadas a las códigos, nodos o casos creados. Por ello, es una herramienta que potencia los análisis de resultados desde preguntas o intereses de investigación concretos, o la selección de casos en segmento del corpus de información.